 Home
HomeWhat Do You Need to Know About the Limits of Machine Learning?

Machine learning (ML) is rapidly transforming into a day-to-day life phenomenon, even if you still believe otherwise. Voice recognition systems like Siri and Alexa, Google search engine, DeepFace (which Facebook uses to suggest friends), Uber’s arrival estimation algorithm, and spam filters in your email inbox are all based on machine learning. Such algorithms are written to help you make decisions faster and accurately. You can complete intricate computational tasks with lots of data with much less effort. Sounds like a perfect troubleshooter!
Could it be that machine learning is the answer to the fundamental problem of making computer systems genuinely intelligent via automated data processing? What are the limits of machine learning and what opportunities does it offer for businesses? It still might be unclear where the boundaries lie.
In this blog post, let’s talk about learning algorithms’ best ‘skills’ and some of the constraints you should consider to gain the utmost benefit from this technology and make it a cost-effective solution for your business.
Why should you care about machine learning at all?
Social media, search engines, e-commerce platforms along with the smart devices’ sensors are continually bursting with tons of potentially valuable customer data. It may include user behavior, demographics, purchase history and other minor details that speak about their Internet habits and preferences. This information known as big data is produced in vast amounts. Oftentimes, it is so unstructured that to process it you need more than just a super powerful computer. Machine learning comes in very handy with its automated big data processing techniques.
ML is not some sort of magic that makes elaborate things happen but a subfield of computer science that consists of software or process algorithm development. Particularly, such algorithms are developed with the ability to learn from statistical data analysis, so the need for exhaustive manual programming is eliminated. How does this work?
The input data that you walk through the computing model gets processed and statistically analyzed to generate predicted outputs (the so-called training data). Machine learning automates the whole processing phase, together with computing models development and results acquisition. What is more important is that it learns from a previous experience (based on relationships between inputs and outputs) to build future most possible scenarios.
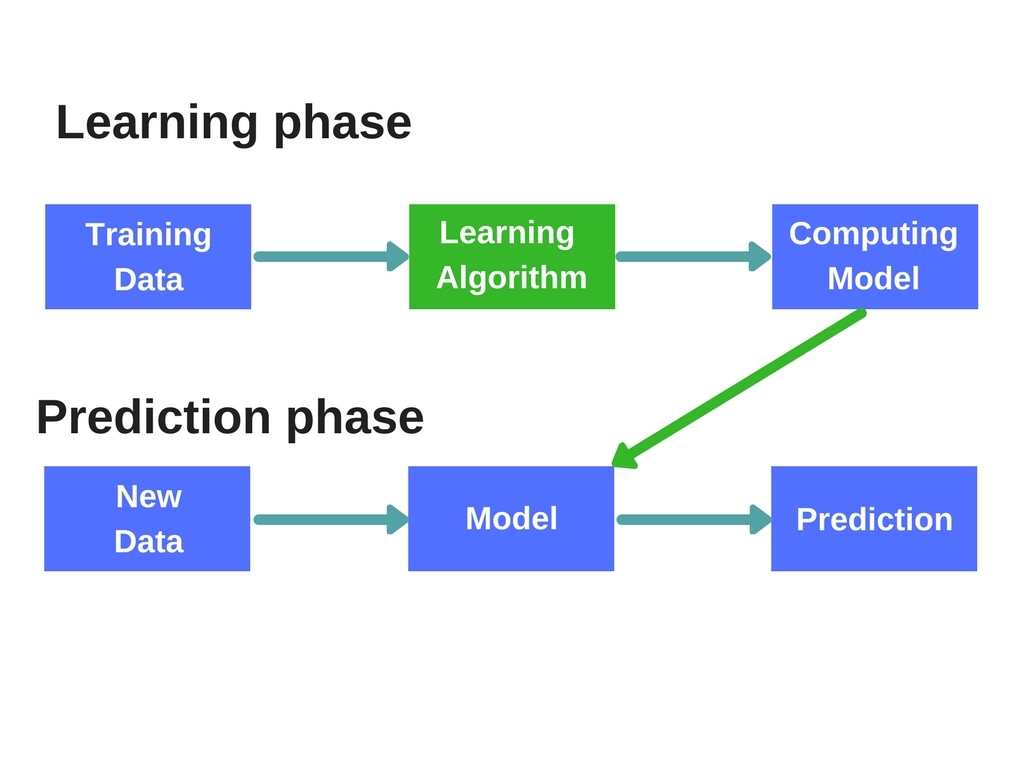
ML is represented with deep learning and artificial neural networks. Deep learning operates enormous amounts of labeled data and teaches computers to learn directly from the text, images, and sound based on a set example. Self-driving cars, recognition systems, voice controlled devices and even scientific research (e.g., cancer medical studies) are some of the examples where it has already been utilized due to its high accuracy and human-level performance.
You can compare neural networks to a human brain, where neuron nodes are connected in a web. Traditional computing programs build data analysis in a linear way. Neural networks are grounded in the hierarchical function of deep learning systems which allow machines to process information in a non-linear manner.
ML wasn’t created to replace people completely. These learning techniques represent a close collaboration of human expertise, knowledge, and technology.
Together, they turn the concept of decision making into a data-driven technology. This technology produces lucrative results and is capable of bringing innovation along with automation into every business sector. Recent research on ML growth by Gartner estimates that by 2021 more than 30 percent of big enterprises around the world will embrace artificial intelligence as part of their operational business model. And here’s why it’s becoming so remarkably favored.
What opportunities does machine learning open for businesses?
Artificial intelligence unveils the hidden power of big data. If a business is operating an extensive customer base, such computing algorithms will simplify customer segmentation, produce more precise targeting strategies and regulate potential risks. With enhanced analysis methods and greater processing speed, you can resolve complex business tasks: it provides automation and gives a way to cost-efficiency.
-
Data mining automation
The digital era produces and piles ups tons of data at such high speed that manual processing of information along with its interpretation is becoming less and less possible for us humans. Data mining is the consecutive process of database examination and data exploration that results in the generation of information that you can use to make a decision. With machine learning techniques, data mining process can be automated. Information that it generates builds credible predictions and assumptions.
-
Ability to learn and improve in time
Machine learning systems of specific software or programs learn to build assumptions by applying previous results and experience. This process is neverending. Algorithms get better and better at “understanding” what events will probably occur. The more learning cycles the system completes, the higher is the probability that the outputs produced by the system would be accurate.
Real-time market research, economic modeling, assessments of services and goods consumption are several examples of how ML can assist with building prognoses and inform about upcoming changes.
-
Data-rich task automation
ML is about the development of both software products and autonomous computer systems that perform their data generation and analysis tasks without constant manual reprogramming. It allows you, as a business owner, and your employees to concentrate efforts on other business goals and endeavors.
Google’s search engine indexes websites and Apple’s Siri replies to questions using this automation feature. For businesses, task automation means better delivery, higher quality services and an innovative approach to business growth. It may include building algorithms used for bank fraud detection and prevention, face recognition in biometrics authentication, and medical diagnostics.
In the past, machine learning was difficult to implement because of complex and costly computations. But at present, the technology situation has changed, making ML an accessible and affordable solution — and even the foundation of your business idea. We can also speak about open-source tools for such algorithms. To name a few, these are scikit-learn for machine learning in Python, Apache Mahout for Scala, Google’s TensorFlow for neural networks. It’s not a miracle anymore. So, should you adopt it too?
Machine learning is not made only to support the big players on the market; at least not anymore. Small businesses can benefit from ML as much as big enterprises do. Consider this. There was a time when startups and small companies were eagerly adopting such immense novelties as SaaS and cloud services to run their internal processes effectively and securely. Artificial intelligence has moved to the top of the list of adoptable technologies because it is customizable. With it, you can automate workflow, simplify communication with different categories of customers and improve your development strategy.
Now that you have an idea of what machine learning can do and how it works, you may start thinking about giving it a try. But like any other technology, ML has its limits and these can’t be ignored. Let’s see what they are and how their understanding can help you avoid systems’ undesirable behavior and unexpected outcomes.
Understanding the limits of machine learning
Machine learning offers an innovative approach to app and web development. But what should you take into account if you choose it as a tool to develop or grow your startup or business? While the technology is powerful, it’s also going through improvements and requires you to adhere to a number of rules.
-
Errors occurring because of insufficient, excessive or unknown data
When it comes to data, predictive algorithms won’t be able to learn in time if you don’t provide sufficient inputs or go beyond the system’s capability. Sounds quite simple, but this is something to consider before you decide you want to ride this innovation wave.
Data is the most important qualifier. It decides whether machine learning is the right choice for your task or problem. Note that each application requires separate training… Ask yourself if there is a suitable set of data to “feed” it to the system. What if you need any historical data? How are you going to acquire it (buying information or generating the necessary amount of introductory inputs on your own)?
Assume you’ve already got suitable statistics to support the system’s learning process. What if you initiate a task that brings in a new type of data the system hasn’t been trained to recognize? There is a high chance that the results it delivers will be far from being true. The more important this new data is, the bigger impact it will make on algorithm computations and model’s training abilities.
A similar problem can be driven by an overwhelming amount of data you add into the system whose machine learning model hasn’t been built and additionally trained to process so many new parameters simultaneously.
-
Training time
To become an accurate and reliable solution, any artificial intelligence software needs to be trained and taught. Any significant computational results are achieved only over a certain time span. The model’s reliability is measured over its performance and processing of different sets of input data. During the training stage, the system would require building an accuracy assessment strategy. You’d need to make corrections once you notice the reliability score is below that which is permissible.
-
Approximation of results
Even though ML has already gained significant achievements, keep in mind that the analysis results it produces can’t guarantee a 100% accurate answer. There is always a slight chance for error and uncertainty. In many business fields (i.e., bank loan management systems), this limitation is no longer regarded as a serious drawback. It is sometimes more important to have at least some prediction than have no information at all.
In the case of an approximation limitation, it’s more essential to understand types of errors that can be produced to make a wise decision after all. Besides, when a system works and learns, it collects both necessary and undesirable biased data (which you’ll need to control and remove).
-
Data interpretation
ML remains a computer algorithm that cannot capture the meaning of computational results. Information that you obtain as a result of input processing is a set of data that machines haven’t learned to understand or generalize. This explains why machine learning requires human involvement.
If you’ve considered all these basic restraint factors with data and feel certain you can overcome them, there’s one more thing that requires your attention. Assess the economic aspect of adding ML to your business processes. Will the new approach pay off vs. the cost of investment? This includes expenses for collecting data, storing it, and cleaning irrelevant data; software development, deployment and maintenance; and the system’s integration with your workflow or internal processes.
Let’s summarize!
So, what should you do about machine learning now that you’re aware of its limitations? It primarily depends on your budget and your business objectives. The advantages that ML offers along with the challenges it poses can’t be regarded as an unquestionable truth. It will always depend on how complex ML models are and what problems they will be trained to solve. Data sets and their quality play a key role in overcoming the processing limits.
Content created by our partner, Onix-systems.