 Home
HomeBusinesses’ Guide to Machine Learning Model Development

Whether you’re curious about artificial intelligence, wonder how to create a machine learning model for business purposes, or are looking for help with your project, you’re in the right place!
Alternative Spaces has accumulated extensive knowledge and experience in developing artificial intelligence (AI) and machine learning (ML) solutions, study of data, ML model training and fine-tuning, and solving various research problems in this field. Whatever your needs, we are here to help!
Table of contents
- Considerations before Building a Machine Learning Model
- Building an ML Model in 3 Steps
- Best Practices of ML Model Deployment and Maintenance
- Alternative Spaces’s Experience in Machine Learning
- Conclusion
- FAQ
The exponential growth of global data volumes and understanding of the benefits of AI drive the adoption and implementation of machine learning models for business purposes, from recommendation engines and chatbots to anti-fraud monitoring of financial transactions.
Read also: 10 chatbots trends & latest statistics
This article intends to explain the process of machine learning from a business perspective and share some best practices to help you conduct a successful ML project.
Like any IT project, it should start with the discovery phase: you need to clearly understand and formulate your business needs and requirements and understand whether you need to build machine learning models in the first place.
Considerations before Building a Machine Learning Model
Before you embark on building an ML model, you should consider several crucial questions, which can be grouped as follows:
1) Understanding the business problem
Your ML model development journey should start with understanding the problem you aim to solve through the power of machine learning. Only a deployed model fully aligned with your business’s objectives will bring maximum value. You will want to agree on and set clear goals that will determine the project requirements and plan.
The key questions to answer are:
- What is the business’s objective for the project?
- How can ML help you reach that objective, at least partly?
- Will this ML model power a brand-new product or an existing system?
- Is there a solution to the problem that doesn’t involve ML? If yes, is it more time- and cost-efficient than a possible ML solution?
- What type of algorithm does this problem require?
Building a brand-new ML-powered product is more costly and time-consuming, not to mention riskier, than developing an ML algorithm to improve and extend a product with proven effectiveness. It’s best to base a new product on a baseline solution and enhance it with ML down the line.
ML model building requires experimentation, creativity, and diligence, even from experienced developers. There are few boilerplate solutions, and they don’t always generate the best results. For this reason, we recommend engaging ML experts as early as this stage of the project to make better decisions.
2) Understanding the project feasibility
Machine learning model development can be resource-intensive and expensive. You need to determine its feasibility from business and implementation standpoints. This includes assessing the human, technical, and financial resources required for the project against its potential impact or return on investment (ROI).
The following questions may help you identify some of the challenges to building machine learning models for your business early on:
- Who will be responsible for the machine learning project?
- Does the company possess sufficient financial, technical, and human resources and skills for an ML project? Does it have the time?
- Have experts reviewed the project’s technical, business, and deployment aspects?
- Is the business willing to invest in machine learning?
- Will the employees understand and support an ML solution implementation?
- Will it require or entail any cultural, structural, or other changes to the business?
- Are there any existing or potential ethical considerations or regulatory hurdles?
- Will the ROI or impact of the ML model implementation offset the costs and efforts associated with the project?
- What data is necessary to train ML models? Can you obtain a sufficient quantity of quality data?
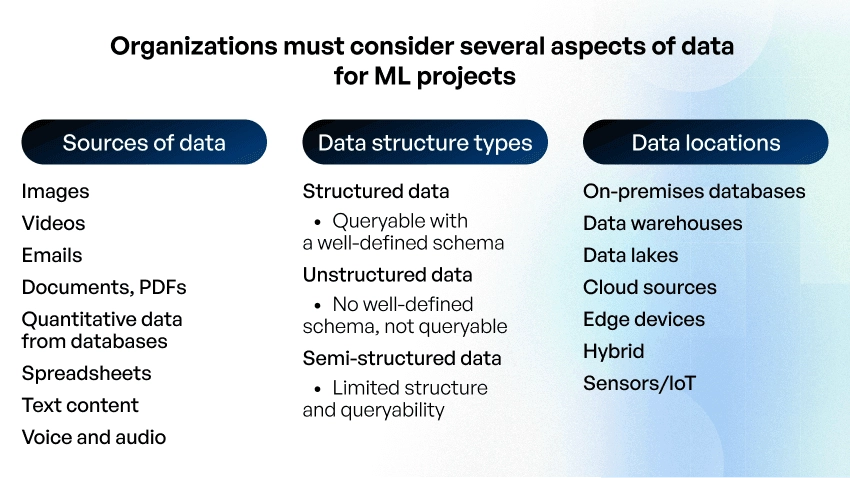
10. Is it necessary to build a machine learning model from scratch, or can pretrained models be deployed instead?
Instead of creating new ML models for solving the formulated problem, it may be possible to apply transfer learning to reuse an existing model. This will cut down on the project resources, especially for supervised ML projects.
Even ready-made ML models that are already trained and freely distributed still need to be correctly integrated into existing systems and business processes. This is a considerable chunk of work. Moreover, specific businesses usually require niche solutions, which may call for retraining or at least fine-tuning the model.
If your company lacks the required technical talent or can’t recruit them locally, you may need to outsource the job. The latter option may result in significant money saving and a faster release.
ML projects involve several experts:
- A data engineer analyzes business data from various sources and ensures that the required amount of quality and up-to-date data is accessible in a cost-effective way.
- A data scientist performs data preprocessing and feature engineering, builds ML models, and chooses the model that best meets the business’s requirements.
- An ML engineer makes sure that the built model produces results reliably, monitors its outcomes, and assesses the need for retraining.
- A web developer builds the presentation layer component to invoke and present the model’s results to the stakeholders.
- A DevOps engineer is in charge of deploying and updating the system.

3) Understanding success criteria
You should develop answers to the following questions:
- What are the ML model’s expected inputs and outputs?
- What criteria define the project’s success?
- How will your business measure the benefits the model yields?
Precision, accuracy, recall, and mean squared error are typical machine learning metrics, but it’s essential to prioritize specific business KPIs.
Once you’ve got clear positive answers to most of these questions, you may proceed to planning your ML model development project. The process must be properly planned and managed from the beginning so that the model is ready on time, meets the business’s requirements, and furthers its goals.
The final product’s quality largely depends on the quality of input data you’ll feed to the model during the training. Therefore, it is also necessary to allocate 40-50% of total project time for data collection, exploratory analysis, preprocessing, labeling, etc.
We can broadly classify the main machine learning steps as follows:
- data exploration and preparation
- building machine learning models
- model evaluation and fine-tuning
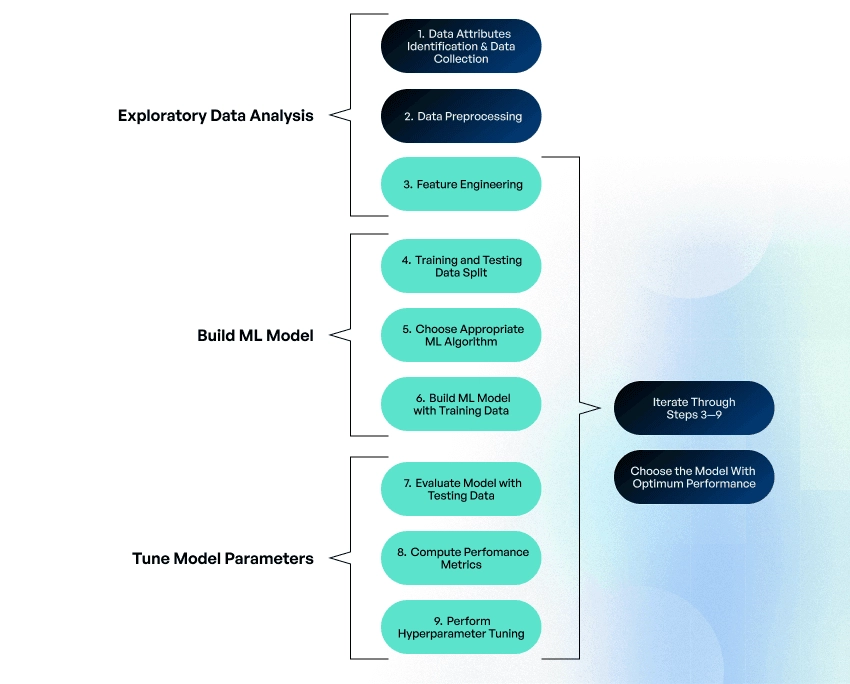
The next chapter will provide the details and tips on each step.
Building an ML Model in 3 Steps
1) Data collection, exploration, and preparation
You need large arrays of relevant, clean, and well-structured training data for creating machine learning models: they must learn the relationships between input and output data from a training dataset.
The following questions will help identify your data needs and determine your data requirements and quality:
- What is the quantity and quality of your present training data?
- How will you split the data collected into test and training sets?
- How will you label data for a supervised learning task?
- Can you use a pretrained ML model?
- Are there any special requirements, such as accessing real-time data on edge devices or other hard-to-reach sources?
- How will the model operate on real-world data once deployed?
- Will the model be used offline?
- Will it operate in batch mode on data fed in and processed asynchronously?
- Will it be used in real time, working with high-performance requirements to provide instant results?
- Will the model be trained once, in iterations with versions deployed periodically, or in real time?
Real-time model training imposes many requirements that may be prohibitive for some setups.
Unsupervised ML models don’t require labeled data, so the training dataset will contain only input variables or features. Supervised machine learning models are trained on datasets comprising input variables and labeled output variables, so a data scientist should prepare and label the data.
The data scientist also needs to determine whether real-world data differs from training data or test data differs from training data. If so, they need to choose the approach to the model’s performance validation and evaluation.
The data preparation tasks may include:
- Collection of data from various sources
- Standardizing data formats and normalizing data across different sources
- Replacing incorrect or missing data
- Data enhancement and augmentation, e.g., by using third-party data or multiplying image-based datasets if the core dataset is insufficient
- Adding dimensions with pre-calculated amounts and aggregating information as needed
- Removal of redundant, irrelevant, ambiguous, or confusing data
- Noise reduction
- Anonymizing personal or sensitive data, if needed
- Sampling data from large datasets
- Selection of features that identify the most important dimensions and, if necessary, dimensions reduction
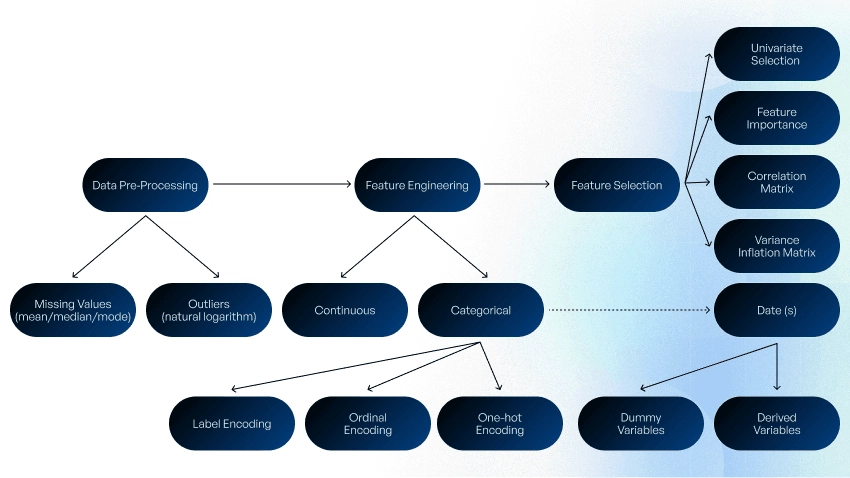
A data scientist should perform an exploratory data analysis to understand the dataset’s features, components, and basic grouping. This analysis includes:
- Data attributes identification, i.e. the identification of predictor/features variables (inputs), target/class variable (output), and data types (string, numeric, or datetime), and the classification of features into categorical and continuous variables.
- Data preprocessing, which involves the identification of missing values and outliers and filling these gaps.
- Feature engineering, where labeled or raw data is processed to convert string, datetime, or numeric data to numeric vectors understandable to ML algorithms. Feature encoding is used to transform categorical data into numerical values, e.g., encode color as 1, 2, 3, and so forth. Ordinal encoding is recommended when there is an ordered relationship between categorical variables, label encoding when there isn’t, and one-hot encoding when categorical variable data is binary in nature.
You can use libraries in R or Python for feature encoding. In some cases, e.g., handling date data types, a collection of dummy variables or derived variables can be created.
Read also: 7 Reasons Why Python Is Best for AI, ML, and Deep Learning
Categorical text data converted into numeric data can be fed to the model.
At this step, you also need to choose the features for improving the model’s accuracy. You may use the following techniques to detect collinearity between two highly correlated variables that contain similar information about the variance within a dataset:
- Univariate selection (statistical measure)
- Feature importance (model property)
- Correlation matrix (identifies features that are most related to the target variable)
The Variance Inflation Factor helps detect multicollinearity, where the model includes three or more highly correlated variables.
Read also: How to Build a GPT Model: Prerequisites and Essential Steps
2) Building a machine learning model
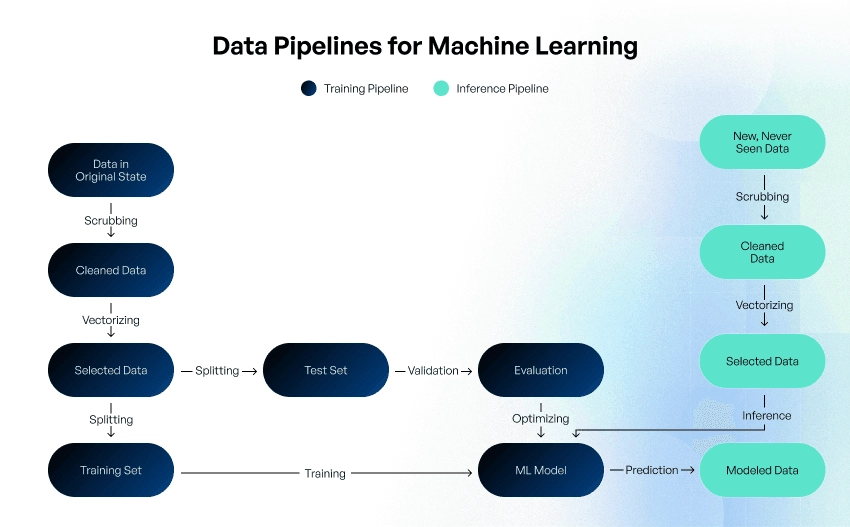
ML models are typically built and tested in a local or offline environment. A model is trained and built using a training dataset, makes predictions using a testing dataset, and is assessed for accuracy and levels of generalization using validation data. Your dataset must be thus split into the training, validation, and testing sets using a ratio of 80/10/10 or 70/15/15.
The next step is to choose the machine learning approach and algorithm most suitable for the task and the features of the dataset at hand. ML models are broadly split into four types, each with a distinct approach to training:
- Supervised machine learning models are designed to predict outcomes and classify new data. The computer requires direction to learn, and the training dataset must include input and labeled output data.
- Unsupervised machine learning models are mainly used to cluster and categorize data and to identify trends, groupings, or patterns within a dataset. These ML models learn from an unlabeled dataset without any guidance regarding your desired results.
- Reinforcement machine learning teaches systems to make decisions to achieve a specific goal. They learn by interacting with the environment to perform a specific task. When a successful action is performed, reward signals are released, and the system learns through trial and error.
- Deep learning (DL) uses artificial neural networks (ANNs) to learn to identify patterns in data. It is often used for analyzing unstructured data types and tasks like image recognition, natural language processing (NLP), and recommendation systems.
Machine learning algorithms are formulas or instructions that enable models to improve over time by ‘learning’ from experience. Here are several examples of ML algorithms:
- binary classification to divide data into two categories
- multi-class classification to sort data between several categories
- k-means clustering algorithm is preferable for grouping an unlabeled dataset into different clusters when you want to understand the structure of your data
- anomaly algorithm is applicable when you need to pull from seemingly uniform data anything that doesn’t fit with the rest of the data
- support vector machine algorithm for classification or regression problems
- linear regression algorithm (e.g., decision tree regressor, random forest regressor) is suitable for linear regression problems if the outcome to predict is continuous in nature
- logistic regression is recommended for finding discrete values of dependent variables from independent variables if the outcome to predict is of binary nature
- convolutional neural networks are suitable for image recognition, and recurrent neural networks for voice recognition and NLP
For the model’s first iteration, starting with the simplest approach is recommended: use a robust, interpretable basic algorithm and performance metrics that allow enough confidence about data relevance. Simple models are faster to train and iterate, while you can go for fancier algorithms like neural networks later on, if necessary. Easy-to-explain simple models are also helpful for getting buy-in from stakeholders and non-technical partners. Shallow decision trees and linear and logistic regression are good choices.
A minimal set of features allows you to get up and running fast. A reduced feature space also means that computational tasks run faster with a quicker iteration speed. It’s best to consult experts for suggestions.
Neural networks (DL models) may be preferred over regression models (ML models), e.g., for tasks related to images, video, audio, or text, as they introduce an additional non-linearity layer for better results. In this case, pretrained off-the-shelf models may help you build a robust solution quickly and easily.
For instance, a pretrained word embedding model that feeds into a logistic regression classifier may suffice for an initial release of a text processing system. You can fine-tune the embedding to the target corpus later if needed.
It’s wise to consider solutions from Amazon, Google, IBM, Microsoft, or open-source frameworks like Caffe, TensorFlow, and Torch. Each comes with its advantages and interprets datasets in different ways. You may need to experiment with several algorithms until you find the one that yields results most aligned with your goals.
Data scientists usually take a hypothesis-based approach to choosing suitable models. It’s also good to experiment with algorithms and use cases to better understand probability and practice splitting data in different ways.
Once the data is in usable format and you have chosen an appropriate ML algorithm, it’s time to train the model to learn from the training data by applying various techniques.
Continuous training and updates to ML models require training and inference pipelines.
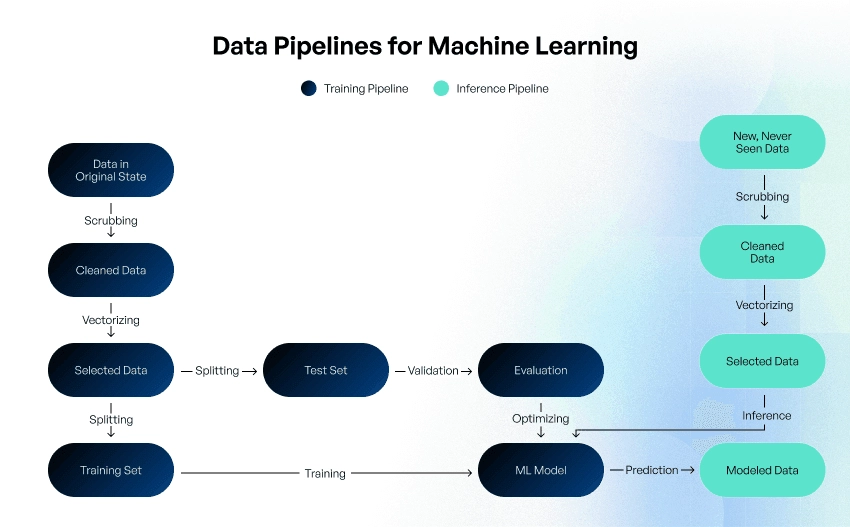
It’s important to avoid overfitting, an undesirable behavior when an ML model gives accurate predictions for training data but fails with new data. The following tricks may help:
- increasing the training data sample to introduce more patterns
- cutting the number of features that reduces complexity
- performing data regularization using Ridge and Lasso methods that reduce errors
Underfitting, when a model cannot accurately capture the relationship between the input and output variables, showing a high error rate on both the training set and unseen data, is equally undesirable. Larger training data samples won’t solve the problem. Instead, the team may increase model complexity, e.g., move from linear to non-linear, add more hidden layers (epochs) to a neural network, or add more features that introduce hidden patterns.
3) Model evaluation and fine-tuning
An ML model’s effectiveness in the real world depends on its ability to apply the logic learned from training data to new data in a live environment.
Model evaluation with testing data is the ‘quality assurance’ among machine learning steps. By evaluating model performance against the established business and operational requirements, you will understand how it will work in the real world and whether you should deploy it.
Prepare to make improvements to the model iteratively and plan comparing new model versions against the existing one.
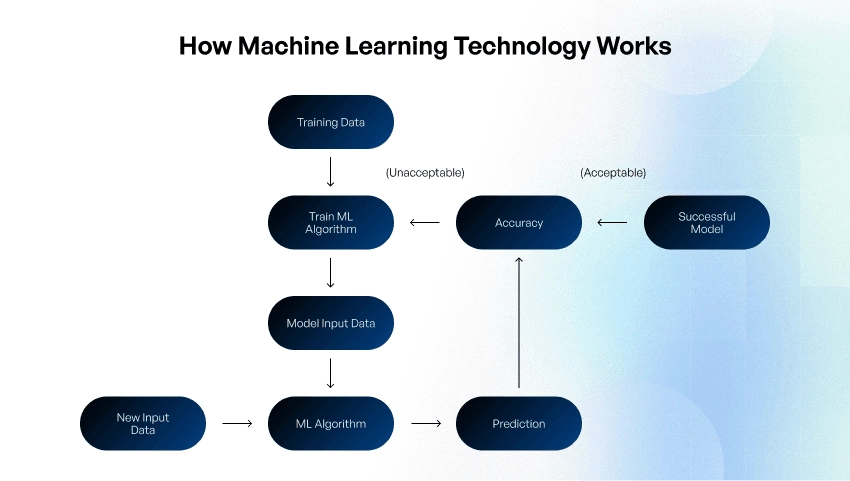
If your team was building several machine learning models, this procedure will help you choose the right final model.
A model’s performance evaluation includes:
- confusion matrix calculations
- business KPIs
- ML metrics
- model quality measurements, etc.
The confusion matrix is used for classification models and coefficient of determination for regression models.
Popular model performance metrics include accuracy, precision, recall, and F1 score (weighted average of precision and recall). It is not recommended to use accuracy to measure the performance of classification models trained with skewed datasets. Instead, computing precision and recall should help you choose the suitable classification model.
Model optimization is an integral part of lowering a model’s degree of error. You can tweak its configuration to improve accuracy and efficiency and optimize the model to fit specific goals, tasks, or use cases.
Optimization of various parameters becomes simpler once the performance metric is set and tied to the impact on business. Understanding the ins and outs of your performance metrics and how they correlate with business objectives is crucial.
You also need to thoroughly measure the model’s performance before any optimization; benchmarks are critical to this task. There are two steps to creating a benchmark:
- Align the metric with the business’s primary objectives. For instance, even 98% accuracy, reasonable in most use cases, would indicate poor performance in a fraud detection system. An initial non-ML solution may provide a baseline value for the performance metric.
- Develop quantification of how each percentage point increment impacts the user and your business. For example, is an increase from 0.8 to 0.85 a game changer in your industry? Will the 0.05 extra points offset the potential added time and complexity? Understanding this tradeoff will help you decide how to optimize an ML model.
Moreover, the understanding of tradeoffs behind a model’s performance will help you avoid wasting time and compute cycles on optimizing a faulty system. This requires an investigation of the model’s output.
Another pitfall is to start celebrating a model’s seemingly good performance too soon. Around 95% of ‘magical’ performance cases rather signal an issue in the system, such as a wrong performance metric, a data leakage, or a balancing issue.
Optimization should stop when it doesn’t drive any incremental business impact.
The assessment and reconfiguration of model hyperparameters is also beneficial. Hyperparameters are model configurations that are not learned or developed through the machine learning process but are chosen and set by the model designer, e.g., the model’s structure, the learning rate, or the number of clusters to categorize the data into.
Thousands of parameters and hyperparameters have to be tuned considering the model architecture, the choice of a class of objective functions, input features, etc. Historically, hyperparameter optimization was a trial-and-error process, but currently, optimization algorithms like the Bayesian optimization help with rapid assessment of hyperparameter configuration to identify the most effective settings.
The random forest algorithm takes maximum depth, maximum number of features, number of trees etc., as hyperparameters that can be tuned for improving model accuracy. The batch size and the number of layers, epochs, and samples apply to ANNs.
It is also recommended to use grid search to find a model’s optimal hyperparameters.
Sometimes, improvement in model accuracy may result from overfitting or underfitting. Cross-validation helps prevent this error by validating a model’s effectiveness against unseen data.
Cross-validation techniques are categorized as follows:
- Non-exhaustive cross-validation techniques will create a randomized partition of training and testing subsets.
- Exhaustive cross-validation techniques will test all combinations and iterations of a training and testing dataset. This approach provides more in-depth insight into the dataset but takes much more time and resources.
This is it. Now you know how to build a machine learning model. However, your ML project doesn’t end here. If your newly trained model fails, you may need to repeat the process, starting from feature engineering, all over again until you get something you can roll out into production. Unfortunately, even models that worked well in lab environments often end up in the proof-of-concept limbo.
If you are confident about your model’s viability, you can release it into the wild (deploy) to start performing the task for which it was trained and bringing ROI.
After importing the new ML model into an app you’re building, deploying it into a web back-end, or uploading into a cloud service, you need to maintain it in production environments. Moreover, in the real world, where source data and business goals change all the time, models require continuous testing, performance monitoring, and multiple retraining iterations to provide valuable, reliable, and desirable results.
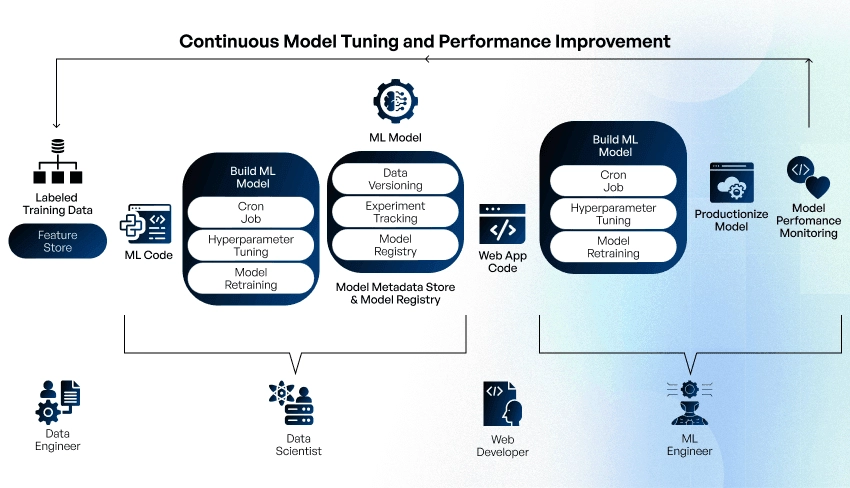
Learn more: The AI Life Cycle: Unlocking Business Value through Strategic Implementation
Best Practices of ML Model Deployment and Maintenance
Model operationalization includes the following steps:
- Model deployment combined with continuous measuring and monitoring of its performance
- Continuous iteration on the model’s different aspects to improve its performance
- Measuring the model’s future iterations against an established baseline or benchmark
Several deployment scenarios are possible:
- in a cloud environment in case of high computing requirements for building a DL model
- at the edge
- in an on-premises or closed environment
- within a closed, controlled group
The trained ML model must be serialized for deployment into TEST/PROD environments. The most common model distribution formats are:
- pickle for ML or DL models developed in Python
- ONNX (Open Neural Network Exchange format)
- PMML (Predictive Model Markup Language XML-based format) for models created using logistic regression and ANNs
Containers are a popular environment for deploying ML models. Containerization streamlines updating or deploying model parts and provides a consistent environment for its functioning. Containers are also highly scalable.
Developers build a docker image bundled with training and inference code, training and testing datasets, and the model file for future predictions. Once the docker file is created, they can build a CI/CD pipeline using Jenkins or another tool. This docker container image can be exposed as a REST API for external stakeholders to access this ML model from on-premises or public cloud.
Open-source platforms like Kubernetes are used to manage containers and automate scheduling and scaling tasks. Kubeflow, an ML toolkit for Kubernetes, can be helpful for packaging and managing multiple docker containers.
The model can also be packaged as a .jar file before being deployed as a prediction service.
Some other ML model deployment best practices are:
- Leveraging DevOps tools to automate some ML model development and deployment steps saves time that can be allocated to better model retraining.
- It’s recommended to implement logging while exposing ML models as APIs, capturing input features/model output to track model drift, application context to debug errors, and, if multiple retrained models are deployed in production, model version.
- It’s better to manage all the model metadata in a single repository.
One can deploy ML models to perform prediction either in the offline (batch) inference or online (real-time/dynamic) inference mode:
- Batch inference is the process of generating predictions on a batch of observations on a recurring schedule (e.g., hourly or daily). These predictions are stored in a database, available to developers or end-users.
- Online inference is the process of generating ML predictions in real time upon request, typically on a single observation of data at runtime. Frameworks like Python Flask or Streamlit libraries are used to develop interactive web applications and invoke the model using its HTTP endpoint.
With each iteration on the ML model in production, the team should strive to:
- incorporate the current and predictable requirements for the model’s functionality
- expand model training to introduce greater capabilities
- improve model performance and accuracy, including operational performance
- address data drift, i.e. underlying source data pattern changes due to seasonality or other real-life factors, or model drift (changes to the statistical properties of target variables, e.g., when the definition of a fraudulent transaction changes)
- determine operational requirements for different deployments
The predicted outcome is continuously compared to the actual value during model performance monitoring. In some scenarios, an old model and a new model run in parallel to understand the variation in their performance.
The most accurate way to assess the model drift is to measure the F1 Score combining the precision and the recall of a classifier metrics. You should retrain the model when the F1 Score falls below a certain threshold, at regular intervals for batch inference, or as soon as the data is available for online inference.
Elastic’s Logstash and Fluentd are popular tools to help with collecting model logs and prediction logs.
Periodic model retraining is essential. You can do it:
- biweekly, monthly, or quarterly, as the underlying source data will likely change significantly over the same periods; this requires scheduling a cron job to retrain the model at predefined intervals
- whenever changes in the source data occur
- when the model performance deteriorates
- as demanded for audit and compliance purposes
ML models’ architecture can be updated to increase their prediction power, and features can be added and removed as your business evolves.
Here are a few tips on updating an ML model:
1) Set up the pipeline infrastructure to train and evaluate two or more model versions concurrently. There are two great methods to evaluate new models:
- An online A/B test is suitable for most cases. For example, in a recommendation system, you can measure any increase in user engagement among a random group of viewers exposed to the new version compared to viewers seeing the baseline recommendations.
- You may also run an experiment without surfacing the output in production, for example, for a classifier where you have access to the labels. A significant model update may run in a staging flow for several weeks before you are sure you can move it to production. When possible, run experiments offline so that possible performance deterioration won’t impact users.
2) Consider possible variance in performance metrics. You need to run the variant model more than once to understand its impact. Model performance can vary due to random parameter initializations, data division between training and testing sets, and other factors. Verify its performance over time, between runs, and based on minor differences in hyperparameters. Inconsistent performance could signal bigger issues. It’s also helpful to check whether performance is consistent across key segments in the user base. If not, you may need to reweight the metric to prioritize key segments.
3) Avoid overfitting when optimizing and account for it in your comparison strategy. For example, using a fixed test dataset can make your model optimized to those specific examples. You may mitigate these problems by practicing cross-validation, changing the test dataset, using a holdout, regularization, and running multiple tests whenever random initializations are involved.
4) Consider the model’s stability over time. Occasionally, stability may become preferable over marginal performance improvements and may be incorporated into your model performance metrics. For example, the model may be retrained quarterly, and the performance may steadily increase. If your metric is good, this means that performance is improving overall. However, individual subjects may have their predictions changed even with the overall increasing performance, causing a negative experience for some users. Here are several techniques to mitigate this effect:
- Consider the tradeoff between the improved performance and the impact of changed predictions and the work required to manage that. Make significant changes to the model only if the performance improvements justify the costs.
- Choose deep models over shallow models only when the performance gains are justified.
- Calibrate the model’s output, especially for classification and ranking systems. Calibration highlights changes in distribution and reduces them.
- Check for objective function condition and regularization. A poorly conditioned model has a decision boundary that changes wildly even when training conditions change slightly.
While retraining models multiple times, you must keep track of model performance and the features and hyperparameters used for retraining. You need a well-defined, reproducible process to implement the end-to-end ML operations keeping the model up-to-date and accurate in the production environment.
Hyperparameter tuning during model retraining can entail some changes to the model code.
You will need an automated model pipeline, which typically includes three types of stores:
- Feature store for data extracted from various source systems and transformed into the features as the model requires. The ML pipeline takes batches of data from the feature store to train the model.
- Metadata store is a centralized model tracking system containing the training dataset version and links to training runs and experiments at each pipeline stage. It facilitates the model’s transitions from staging to production to being archived. The model training occurs in one environment, and the deployment in other environments where the model inference is performed by specifying the remote model file path. The metadata store is used to track model experiments and compare its performance afterward.
- Model registry contains all trained models’ data: trained model version, training date, training metrics, hyperparameters used for training, predicted outcomes, and diagnostic charts (confusion matrix and ROC curves). The intended user’s requirement determines the choice of the appropriate model from the registry.
The model metadata store and registry can be implemented using a lightweight database, such as SQLite, and a set of Python functions. You can also use open-source or proprietary products, such as MLflow on Databricks that facilitates model management using a GUI or a set of APIs.
Model version management is another mandatory activity. The source data, the model training scripts, the model experiment, and the trained model are versioned in the code repository. Data Version Control (DVC) and AWS CodeCommit are some open-source tools that may help with model version management.
Business goals and requirements, technology, and real-world data continuously change unexpectedly, calling for new model modifications or deployment into different endpoints or systems. The surefire way to succeed with ML projects is to continuously strive for improvements and better ways to meet evolving business needs.
Read also: 8 Effective Data Mining Techniques for Business Success
Alternative Spaces’s Experience in Machine Learning
Alternative Spaces has a history of building and training machine learning models for various business and non-commercial purposes, such as:
- image classification
- language identification
- news categorization
- social media content analysis
- social media sentiment analysis
- translation of graphic novels and webtoons into multiple languages
- comic strips animations
- conversational engines based on NLP & DL
- image denoising in info-communication systems
- product type and style recognition
- face recognition and manipulations in livestreams
- crowd video analysis and behavior pattern recognition
- mapping and geographic information systems
- green energy output prediction
Speech2Mindmap is a recent example of our team’s work. We have designed a distributed system that processes speech to structured text sequences and returns ordered graphs in almost real time. The main idea of the mind map graph is to show the speech flow and determine its theme and how it changes over time.
The project’s technology stack included:
- Programming language – Python 3.10
- Python libraries:
– Pytorch – ML framework library that helps to load ML models, evaluate the results, and build own ML solutions. In this project, we used model evaluation that helped to get the embeddings for the phrases and utilities from this framework to evaluate the similarity score using cosine similarity metrics.
– Whisper – OpenAI’s automatic speech recognition neural network. Its base model was used here to extract text from speech.
– Spacy – a library for NLP that can distinguish noun phrases and named entities (NP/NE) in a text using a preloaded model.
– Sentence-transformers (SBERT) – a state-of-the-art BERT model modification that embeds phrases into n-dimensional space. Unlike BERT and RoBERTa models, it supports evaluation of huge numbers of embeddings (words) at low cost time- and memory-wise.
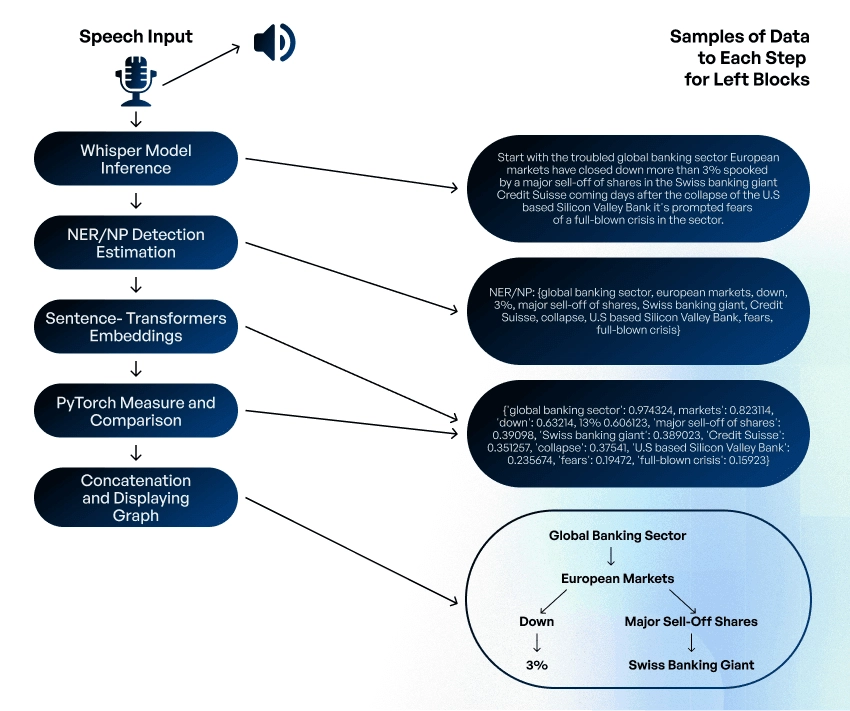
Speech2Mindmap works as follows:
- The Speech Listener module processes human speech from the microphone in real time to an mp3 file. In the case of video/audio processing, it extracts the audio track from the file using ffmpeg library and saves it to an mp3 file.
- Whisper inference processes the speech streams bytes and returns the text from the speech. In this part, we use ML model inference designed by OpenAI.
- NER/NP estimators with Spacy core process the text, bringing it to a homogeneous form. Spacy estimator model is used to remove stopwords, most common words, and the punctuation, as well as to detect the NER/NP phrases.
- SBERT create embeddings for each entity. SBERT architecture is used for defining the numerous sentence embeddings.
- Pytorch capabilities define the measure of similarity between embeddings and text and similarity between all embeddings.
- The mathematical operation for comparison is employed to identify the most significant phrase in the text, characterized by the highest similarity score. Additionally, it discerns several other pertinent entities related to this phrase, arranged in ascending order based on their value. Entities that exhibit a low similarity score or a negative score are excluded from the array.
- A graph contains roots, nodes, subnodes, etc., represented by NP/NE. After ordering the phrases, the entity with the highest score is designated as the graph’s root, while the other words are identified as its nodes. For each node in the graph, their children are defined using the aforementioned operation.
- The graph builder function processes an array consisting of a single root and multiple nodes, each potentially having its own subnodes, to construct a structured graph representation.
- In cases where additional graphs precede the current speech graph, it’s essential to compare the root node of the current graph with the terminal nodes of the preceding graph. Additionally, if a subnode in the current graph matches the root of the previous graph, concatenation with the predefined entity should be executed.
The designed system is a minimum viable product (MVP), and the following enhancements to the system are possible:
- Add support for filtering sensitive information during text processing
- Adjust the filtering of data with Spacy tokens checks
- Apply the fine-tuned model of Spacy or dolly 2.0 for more precise detection in NE/NP
- Wrap the system into a web application using Flask or FastAPI libraries or to CoreML/ONNX solution
- Add support for caching data using Redis DB or ElastiCache solution with AWS
The designed solution can be implemented into a mobile application with a web-based core or apps running on mobile capabilities (CoreML for IOS and ONNXRuntime for Android).
Conclusion
Machine learning empowers businesses to gain crucial insights, make better-informed decisions, automate processes, improve security, and more. ML systems offering advanced capabilities, once considered out of reach, are likely to transform entire industries shortly.
Businesses that want to survive and thrive in today’s science, technology, and data-driven world have no choice but to explore ML applications, which become increasingly affordable and accessible.
They often say that the formula for successful ML projects is to think big, start small, and iterate often. We dare to add one more component: engage professionals early.
For instance, Alternative Spaces’ ML team has worked in the areas of
- NLP (text classification, message generation, etc.)
- enterprise chatbots
- smart library systems
- computer vision
- drone and satellite AI
- safety acoustic systems
- chemoinformatics and computational chemistry
- GPT-3 and BLOOM
- prediction
- optimization, etc.
Whether you want to create a custom machine learning algorithm or need help with fine-tuning and incorporating an ML solution with your system, we are here to help!
FAQ
How to make a machine learning algorithm?
It takes the following steps to create a machine learning algorithm:
1) Choose a supervised or unsupervised learning algorithm type according to your project requirements. Learn more about the chosen algorithm to understand its functionality, where it’s used, and when it shouldn’t be used, to make sure you’ve picked the right one.
2) With the help from business stakeholders and data scientists, prepare the necessary datasets, which includes:
- collecting data from relevant data sources
- assessing the condition of the collected data and creating data profiles
- organizing the datasets in the format required by the algorithm, which may include standardizing values in several columns
- improving the dataset quality
- after analyzing the input variables, modifying raw data into features
- dividing the dataset in two: one for the ML algorithm training and the other for testing
3) writing the pseudocode for the ML algorithm
4) coding the ML algorithm, which should include a structured code review process
5) utilizing the training dataset to train the newly created algorithm, reviewing the ML model created during this training, analyzing the outliers and any data errors, and reiterating the training and review processes
6) testing the ML algorithm, which includes
- executing the algorithm and creating an ML model
- reviewing the output with a focus on outliers and exceptions
- making the necessary corrections in the input datasets
- rerunning the tests
- reiterating the review process
- reviewing the comparison results and analyzing the differences
- taking corrective actions if applicable
What programming languages are the best for building machine learning models?
AI/ML developers and data scientists most commonly choose Python and R due to their extensive libraries, community support, and flexibility in handling ML tasks. Python enjoys arguably the best reputation. A vast ecosystem of libraries like TensorFlow, PyTorch, Scikit-learn, and Pandas makes it ideal for a wide range of ML tasks. Its simplicity, readability, and the fast and easy development process using Python also contribute to its popularity.
R is favored in statistical analysis and data visualization and is particularly good at specialized statistical techniques.
Java, C++, and Julia are also used in ML. For example, Java offers significant advantages in terms of integration, performance, security, and compatibility in specific contexts.
How to train a machine learning model successfully?
Here are several best practices for training your ML model:
- Keep intermediate checkpoints in building the model to keep track of its hyperparameters and associated performance metrics. This enables incremental model training and good judgment when measuring performance against training time.
- Carefully build and annotate your training datasets. When compiling the dataset, consider the defects and defect labels, tag defects, and monitor the model to ensure it uses the right training data.
- It’s important to use image annotation when generating the training datasets for computer vision models. An ML data labeling system will be helpful when collecting such datasets.
- Using image transformations in training datasets to expand your training distribution with image processing helps build stronger models.
- The use of real-world production data for model training improves prediction correctness.
- Start by overfitting, i.e. training the model on a small set of data samples, and evaluating the results. Training with a handful of random data points as a sanity check will help avoid errors before feeding it more data.
Do I need a lot of data to create a machine learning model?
The answer depends on your project’s specifics, such as:
- the type of problem the ML model must solve
- the model’s complexity
- the quality and accuracy of the dataset
For example, image recognition or NLP, supervised learning models, and models using multiple algorithms require more data than their counterparts.
How much data does machine learning require?
The more, the better, but the rule of thumb is that the number of rows (data points) should be at least tenfold the number of features (columns) in your dataset.
Around 80% of successful ML projects reportedly use training datasets with more than 1 million records.
However, it is possible to achieve positive results with smaller datasets. It’s also possible to reduce the required amount of data using
- feature selection techniques like LASSO regression or principal component analysis (PCA)
- dimensionality reduction techniques, such as autoencoders, manifold learning algorithms, generative adversarial networks (GANs), etc.
How long does it take to build and train a machine learning model?
The time can vary from several hours to several months, depending on many factors:
- the complexity of the task and the model
- the size and nature of the dataset
- available computational resources
- tuning and optimization
- the ML team’s experience and skill level, and more
Content created by our partner, Onix-systems.
Source: https://onix-systems.com/blog/how-to-build-a-machine-learning-model