 Home
HomeThings to Know Before Building a GPT Model

If the fantastic capabilities of ChatGPT or other applications powered by generative AI made you curious about building a GPT model for your business, here you can learn how it’s done, what it takes, and whether you actually need to do everything yourself.
If you are interested in theory, there are links to articles that explain the fundamentals and how to build a GPT model step-by-step. If you have any questions or need assistance, we are here to help too!
Table of contents
- What is a GPT model?
- The development of GPT models in a nutshell
- What it takes to create a GPT model
- Best practices for building and training GPT models
- Possible solution?
- How Alternative-spaces can help
- Conclusion
- FAQ
Let’s start with the basics: what a GPT model is and how it works.
What is a GPT model?
Generative AI models or foundational models, such as OpenAI’s GPT-3 behind the celebrated ChatGPT, Google’s BERT, another OpenAI product DALL·E 2, ELMo, and others are artificial neural networks (ANNs).
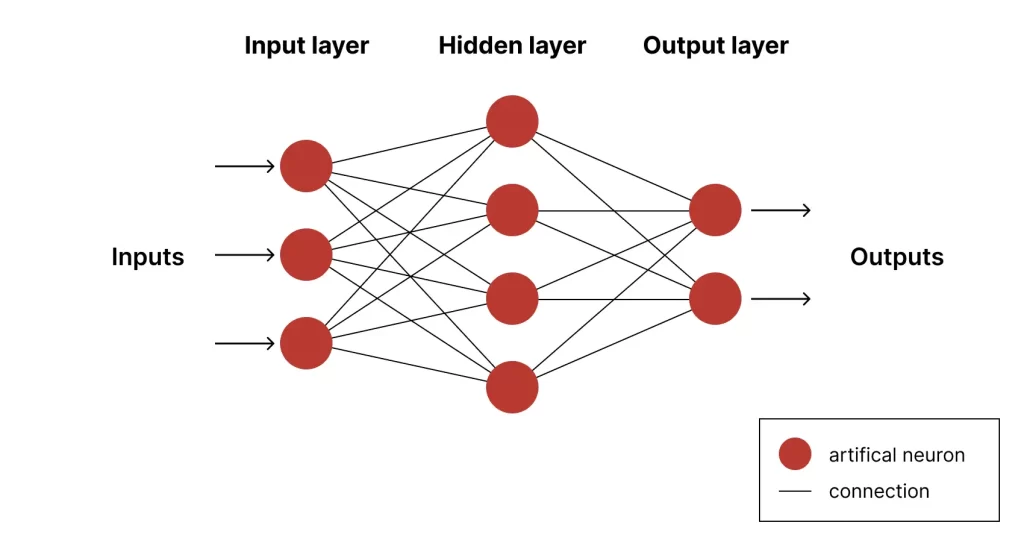
These models can be used for natural language understanding tasks like question-answering or translation. Integrated into chatbots and virtual assistants, these models boost their capabilities.
Read also: 6 Chatbot Trends that Are Bringing the Future Closer
They also have the potential to aid with creative tasks in art, design, architecture, animation, gaming development, movies, etc., and scientific areas like computer engineering.
GPT models are a type of foundational model first developed by OpenAI. They can perform natural language processing (NLP) tasks like question-answering, textual entailment, summarization, etc., without supervision and requiring few or no examples to understand tasks.
GPT is short for “Generative Pre-trained Transformer.”
Generative
These models can generate new data points (text) based on previously learned relationships between variables in a large dataset and a given prompt.
Pre-trained
This term denotes that the models already include a text database, allowing for a better understanding of the structure and patterns of a natural language.
Transformer
The models are based on the transformer architecture of ANNs that is capable of handling sequential data, such as text, understanding language at a deeper level, and generating coherent text even with limited input.
The layers in the transformer structure prioritize words and phrases in user inputs. Self-attention mechanisms enable it to weigh the relevance of words and phrases in the conversation context. Feed-forward layers and residual connections enable the system to understand complex language patterns. Multiple transformer blocks process the user input and generate predictions (output).
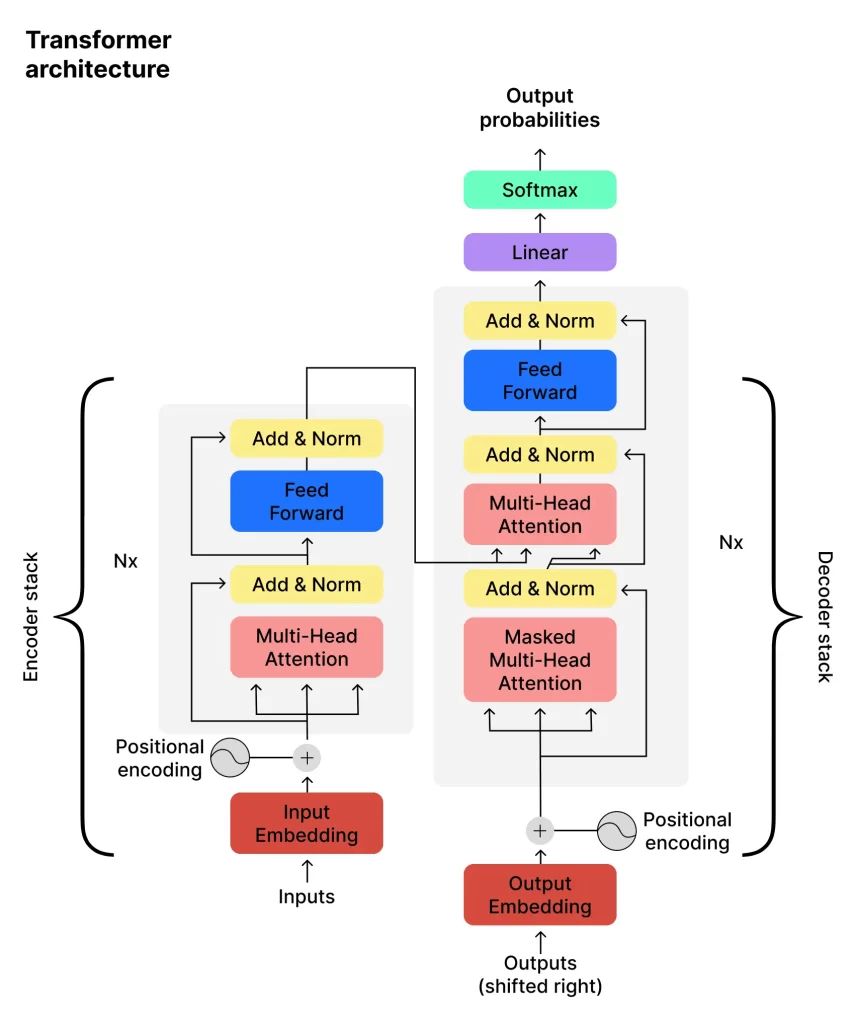
As a result, GPT-3 can generate contextually relevant responses through correct sentences, paragraphs, and entire cohesive texts and perform NLP tasks quickly and without extensive tuning or even examples of data.
Read also: How AI can transform your business
Now, let’s see how OpenAI and its competitors build GPT models to achieve these results.
The development of GPT models in a nutshell
The process of building a GPT model can be roughly divided into five steps.
1. Training data preparation
It takes good-quality text data to build an efficient GPT model, which primarily means that the data should
– come from the same environment as the data that the system will use in the real world
– be representative of reality without reflecting reality’s existing prejudices
– have no gaps
– be unprocessed, since processed data may carry less information than the original data
Text data for large language models (LLMs) can be collected from books, online magazines, websites, and other sources. For example, GPT-3 was trained primarily on the Common Crawl dataset, a scrape of 60 million Internet domains. This included information from outlets like The New York Times and BBC and even sources like Reddit. GPT-3 also ingested content from Wikipedia, historically relevant books, and other curated sources.
Before the text can be used for LLM training, it has to be:
- cleaned to eliminate critical data flaws and irrelevant information, such as HTML tags or irrelevant headers, and standardize the text format
- pre-processed, which includes converting the text to lowercase, tokenizing it into a list of words, stemming, removing stop words, encoding each word into a unique integer, and generating sequences of fixed length
- labeled to add necessary meaning and context to the data
- divided into training, validation, and test sets
- divided into batches to feed into the model during training
- converted to tensor in TensorFlow or PyTorch
2. Model architecture configuration, selection, or creation
The configuration parameters for a GPT model include:
- the number of transformer layers
- the number of attention heads
- the size of the hidden layers
- the vocabulary size
More complex tasks may require more layers or sophisticated attention mechanisms. Longer sequences may require deeper networks, and larger models require more memory and computational resources.
The choice of model architecture is a trade-off between the desired performance, the available resources, the task complexity, and data characteristics, such as the sequences’ length, structured or unstructured data, and the vocabulary size.
3. Model training
The standard approach is to expose the model to vast amounts of unlabeled text from the preprocessed data so it learns to predict the next word in a sequence based on the input context. Depending on the model’s requirements, it can consume the batches randomly or sequentially.
Throughout the training loop, the developers adjust the model’s parameters so that it makes more accurate predictions and achieves a certain level of performance. They can also periodically evaluate the model on the validation set and compare its performance on the validation set to its performance on the training set to check for overfitting.
Those who build a GPT model for enterprise and industrial use may take an intermediate pretraining step. The model is further pre-trained on a closed-domain dataset, allowing for an improved understanding of the concepts and generation of language specific to that domain.
Training on large amounts of proprietary data with unique structure and language helps mitigate challenges in language processing and vocabulary complexity. The resulting model will perform with higher accuracy and efficiency than a general language model.
Finally, the model is fine-tuned for specific tasks, such as text generation, classification, question-answering, and translation. The use of first-party data for training and fine-tuning promotes customization to meet specific use cases and improves the model’s overall performance.
4. Model testing, evaluation, and adjustment
Finally, developers use the newly trained model to generate new text following prompts.
Human evaluation is arguably the most reliable method for evaluating the quality of the generated text. Evaluators have to read and rate the output based on relevance, coherence, fluency, and overall quality.
Other common metrics are the model’s accuracy and perplexity. For example, developers can calculate the accuracy by comparing the model’s predictions to the true labels and the perplexity by assessing how well it predicts the next word in a sequence.
They can also compare the output with that of an existing model, preferably one fine-tuned with the same set of content, as well as with responses generated by ChatGPT.
Additionally, they can improve the model’s performance by varying hyperparameters, changing the architecture of the neural network, or increasing the amount of training data.
5. Model deployment
At this stage, the fine-tuned model is released into the real world and integrated with business processes to deliver tangible results.
The deployment techniques include:
- A/B testing, where the new system is tested on a part of the user base while the rest continue with the historical solution, or silent deployment, i.e. running the new system in parallel to the existing one to ensure that it either matches or improves its findings
- model versioning and iteration
- monitoring
- staging in development and production environments
You may find more information in the following resources:
- Attention Is All You Need, the seminal article about transformers architecture
- Illustrated Transformer by Jay Alammar
- An in-depth guide on Habr, which first explains the basics of the transformer architecture and then provides a step-by-step code implementation to help you build a GPT model from scratch.
- This Medium article offering step-by-step instructions in acquiring and preparing raw data, custom vocabulary extraction, tokenization, and training a model on a specific knowledge domain.
The transformer architecture alone may seem complicated, but unfortunately, it takes much more than knowledge to build your own GPT-4 analog.
What it takes to create a GPT model
Like any other IT project, GPT model development requires:
- Qualified human resources
- Tools and technologies
- Budget
AI team
Candidates for the job should be well-versed in:
- the work of the encoder, decoder, and attention mechanisms within ANNs
- how the transformer architecture processes and generates language
- the techniques of ANN implementation in a deep learning framework
- basic NLP techniques and possible applications thereof
- language modeling
- optimization algorithms (stochastic gradient descent or Adam)
as well as any of the following programming languages:
- Python
- R – a programming language specifically designed for doing statistical analysis with several packages for machine learning (ML)
- Julia – a high-level programming language with features well-suited for numerical analysis and scientific computing
Read more: How to build machine learning teams for AI projects
If you don’t have such programmers or engineers familiar with ML on board, you may recruit them individually, which will take time and effort, or hire an entire team, complete with an experienced PM, from a digital agency or outsourcing vendor like Alternative-spaces. Such dedicated teams are typically more cost-efficient and facilitate a faster project start.
Tools and technologies
Some of the resources required to build a GPT model include, but are not limited to:
- a deep learning framework, such as Keras, Microsoft Cognitive Toolkit (CNTK), PyTorch, or TensorFlow
- a large corpus of training data
- a high-performance computing environment, such as GPUs (graphical processing units) or TPUs – tensor processing units that are better suited for ML calculations
- tools for data pre-processing and cleaning, such as Python libraries NLTK, NumPy, Pandas, and spaCy
- tools for model evaluation, such as task-based evaluation, Turing-style test, BLEU scores, etc.
- services facilitating the training and deployment of a GPT model, such as Amazon SageMaker’s deep learning containers (DLCs) for Hugging Face and SageMaker Hosting
- monitoring tools, and more
Budget
They say that LLMs like GPT-3 are trained on trillions of tokens, have billions of parameters, and cost millions to build.
The training phase will likely consume the bulk of that budget. For instance, a business aiming to build a GPT-3 model alternative might have to shell out some $4,6 million to have it trained on the lowest-priced cloud GPUs.
The hosting aspect also involves choosing between a GPU instance or a CPU instance, where the Service Level Agreement and the model’s intended use for real-time inference determine the number of nodes.
GPT model training costs will likely only grow over the years as the models will become increasingly powerful.

Unfortunately, high budgets are not the last challenge you are going to face. GPT model developers also should be aware of some common mistakes and ways to avoid them.
Best practices for building and training GPT models
Achieve alignment
The goals and values of AI models should align with those of humans. They should be developed and deployed ethically and with social responsibility in mind, be safe to use, and make decisions that are beneficial to humans. The notion of alignment summarizes these requirements.
One way to achieve it is to design the model’s objective function to reflect human values or incorporate human feedback into the model’s decision-making process.
Reinforcement learning from human feedback (RLHF) by reward-weighted regression (RWR) is one of the ways to align the model’s objective function closer with human values. For example, when a model generates responses to prompts, evaluators may score the quality of the responses based on their preferences. The developers then would use this feedback to adjust the model’s parameters until it generates responses that evaluators rate higher.
Reduce bias and toxicity
When training GPT models on vast amounts of text data from the web it’s hard to predict and control the quality of that text. This can result in biased and toxic language in a model’s output.
The proactive approach to this issue includes:
- using first-party data for training and fine-tuning GPT models
- filtering training datasets to remove potentially harmful content
- implementing watchdog models for real-time monitoring of the output
For example, packages like IBM’s AI Fairness 360 provide an open-source implementation of algorithms that detect bias in ML models. The FairML package assesses the relative significance of input features to detect biases in the input data.
Reduce hallucination
A model that is trained on a limited or biased dataset, or when prompts include absurd or incomplete text, may also generate false content or contradict prompts. This issue, called hallucination, can decrease the reliability of the model’s output.

Using sufficient high-quality, diverse training data is one way to prevent hallucination. Developers may also manage it through data augmentation, adversarial training, improved model architectures, and human evaluation to optimize responses iteratively.
Ensure privacy and security
It is crucial to prevent sensitive information from entering into a GPT model that can eventually disclose it to the public.
AI developers should enforce transparent policies designed to prevent the unintentional disclosure of sensitive information and safeguard the privacy and security of individuals and organizations. They should also watch out for potential risks related to the use of GPT models, such as in chatbots, and take proactive measures to mitigate them.
Read also: Best practices for SaaS security (+checklist for startups)
Possible solution?
By this point in the article, you may feel overwhelmed and begin doubting the feasibility of your AI project. The good news is that you actually don’t need to build your own GPT model just like you don’t need to invent a wheel – everything is already out there!
For instance, the latest version of OpenAI’s product, GPT-4, is currently available on ChatGPT Plus and as an API for developers to build applications and services. It’s possible to build a custom GPT-4 model by fine-tuning OpenAI’s base models – Davinci, Curie, Babbage, and Ada – with your training data.
Read more: OpenAI’s Chat GPT-4: Why is it important?
The use of GPT-4 is chargeable, of course, but this cost would hardly amount to the expenses required to design and train your own LLM model from scratch.
Moreover, OpenAI isn’t the only fish in the sea. There are Google’s LaMDA, DeepMind’s Gato, Cohere’s Command XLarge, Microsoft/NVIDIA’s Megatron-Turing NLG, and other less-known open-source alternatives to GPT-4.
Learn more: How much does it cost to use GPT models?
As the commercial demand for AI-powered solutions grows, we will see more scientific institutions, tech giants, and startups create own GPT models. This will lead to a broader choice of high-performing products with better functionalities at decreasing prices.
How Alternative-spaces can help
Alternative-spaces has been developing ML and AI systems, including language and image processing applications, and integrating advanced tech into existing products for years. This amassed expertise helps our clients worldwide to leverage cutting-edge technology to uncover insights, improve decision-making, and create breakthrough solutions for business growth.
Read also: Top 10 Java machine learning libraries & tools for your project
When it comes to GPT models, our software engineers can assist with the fine-tuning and wrapping of your chosen model.
They are also well-versed in ChatGPT development. For example, the СhatGPT API types they’ve worked with include:
- Chat
- Completions
- Edits
- Images
- Embeddings
- Audio
- Fine-tunes
- Moderations
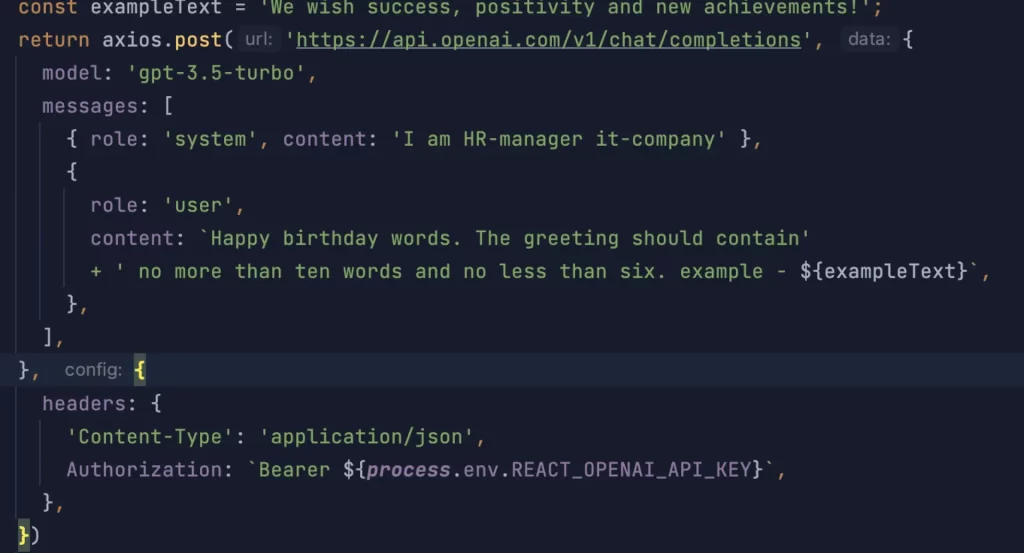
For example, we have recently developed a virtual assistant to perform some HR manager’s tasks. For example, the chatbot generates greetings for holidays and other standard HR-related messages.
Request
Response
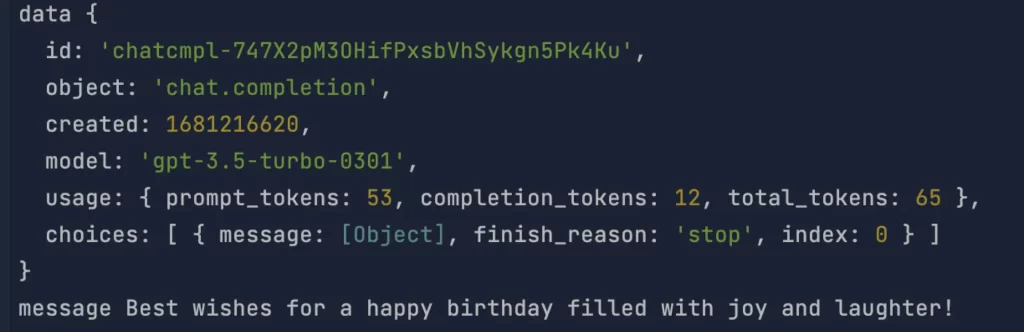
Result

The virtual assistant was designed to operate with minimal human intervention while understanding its role.
ChatGPT’s capabilities allow for delivering more innovative and effective AI solutions tailored to each client’s specific business needs.
Learn more: How to build an app with ChatGPT
Alternative-spaces’s experts can work together as a team for you or cooperate with your in-house team to innovate and deliver tangible results for your business.
If you want to integrate chatGPT into your product or develop another AI-powered solution, Alternative-spaces can help you with every step on the way:
1. Assessment of your needs: Alternative-spaces’s experts will ask about your needs, goals, and requirements, help determine the best way to meet them through technology, and identify the essential software product functionalities and any constraints or limitations that may affect the implementation.
2. Customization: Alternative-spaces can customize a GPT model, ChatGPT, or another solution to suit your specific requirements. This includes fine-tuning an AI model, developing chat flows and conversation scripts, designing the user interface to fit your branding guidelines and the users’ specific needs, and more.
3. Integration with your product: Alternative-spaces’s experts will integrate a GPT or another type of AI model, chatGPT, etc., into your website chatbot, mobile app, voice assistant, or another product, ensuring it aligns with its overall user experience and functionality.
4. Testing and quality assurance: Alternative-spaces’s specialists will thoroughly test the new or modified software solution to ensure flawless performance and usability. They will also provide you with the necessary tools to monitor performance and troubleshoot any technical issues that may arise.
5. Ongoing support and maintenance: Alternative-spaces provides continuing support and maintenance services to ensure that the software product functions seamlessly and remains reliable.
Conclusion
GPT models that take NLP to the next level will likely shape the future of the Internet and software applications and transform activities that have been around for centuries. The capabilities of GPT models that already excel at text summarization, classification, and interaction allow for the creation of innovative solutions for various businesses.
Read also: ChatGPT application ideas to consider
Luckily, you don’t need to build your own GPT model to leverage its benefits. With the right approach, tools, and some help from experts, an existing solution may be adapted to your business to create new opportunities and a competitive edge.
If you want to customize a GPT model, build another ML solution, or need other help on your AI journey, please don’t hesitate to contact Alternative-spaces’s experts!
FAQ
What is the difference between the GPT series models?
GPT-2 is a smaller open-source model with 1.5 billion parameters. Unlike GPT-3, it cannot understand the context or generate long-form text.
GPT-3 has 175 billion parameters and was trained on a much larger and more diverse dataset than GPT-2. It has a more extensive vocabulary and generates more accurate and detailed texts. GPT-3 is not open-source yet.
With 1 trillion parameters, GPT-4 is more creative than its predecessors and can process input in the text, images, and even video format. Ten times more advanced than GPT-3, this model better understands context and distinguishes nuances, resulting in more accurate and coherent output.
Learn more: GPT-4 vs. GPT-3 models comparison
What are the essential steps to building a GPT model?
- Training data acquisition and preparation, which includes data cleaning, tokenization, etc.
- Model architecture selection or implementation
- Training the model to predict the next word in a sequence based on the input context
- Evaluation of the trained model’s output and performance
- Deployment
How much does it cost to build a GPT model?
It’s hard to calculate the cost because it depends on the type of the chosen architecture, the type and quality of the available data, the required computing resources, the number and qualifications of experts to develop it, and other factors. Still, companies that embark on such projects should expect to budget at least a seven-digit number.
Content created by our partner, Onix-systems.
Source: https://onix-systems.com/blog/build-a-gpt-model